
次の C プログラムの説明及びプログラムを読んで,設問1,2に答えよ。
入力ファイルを読み込んで,文字コードごとの出現回数を印字するプログラムである。
〔プログラムの説明〕
(1) 入力ファイルは,バイナリファイルとして読み込む。 入力ファイル中の各バイトの内容(ビット構成)に制約はない。入力ファイル名は,#define で指定する。
(2)入力ファイル中の各バイトについて,文字コード( 16 進数 00 ~ FF で表示する)ごとの 出現回数を求めて印字する。印字例を,図1に示す。
(3) 印字様式を次に示す(記号 ,
, ,
,
 は,図1中の記号を指している)。
は,図1中の記号を指している)。
- 1 行目に,処理したバイト数をの形式で印字する。
- 3 行目以降に,出現回数とその文字コードをの形式で印字する。
ただし,文字コードが 20~ 7E の場合は,文字コードの後にそれが表す文字(文字は,
この冊子の末尾にあるアセンブラ言語の仕様の 1.3 で規定するもの)をの
形式で印字する。文字コードは,64 行× 4 列の範囲に,上から下,
左から右に文字コードの昇順となるように並べる。
(4) プログラム中で使用している関数 fgetc(s) は,ストリーム s から1文字を読み込んで返す。 ストリームが入力ファイルの終わりに達しているときは EOF を返す。
(5) 入力ファイルのサイズは,long 型(32 ビットとする)で表現できる数値の範囲を超えないものとする。
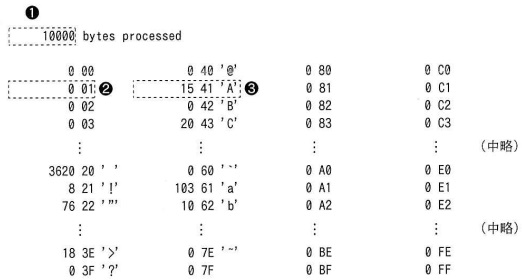
図1 印字例(文字コード順)
〔プログラム〕
#include <stdio.h>
#define InName "sample.c" /* 入力ファイル名 */
int main() {
FILE *infite;
①→ int chr, i;
long cnt;
long freq[256]; /* freq[i]: 文字コード i の出現回数 */
for (chr = Ø; chr <= 255; chr++)
freq[chr] = Ø;
infile = fopen(InName, "rb");
cnt = Ø;
while ((chr = fgetc(infile)) != EOF) {
cnt++;
freq[chr]++;
}
fclose(infile);
printf(" %1Øld bytes processed\n\n", a );
for (i = Ø; i <= 64 i++) {
for (chr = i; chr <= b ; chr += c ) {
if ((Øx2Ø <= chr) && (chr <= Øx7E))
printf(" %1Øld %Ø2X '%c'", freq[chr], chr, chr);
else
printf(" %1Øld %Ø2X ", freq[chr], chr);
}
printf("\n");
}
②→
}
| 設問1 | プログラム中の に入れる正しい答えを,解答群の中から選べ。 |
a に関する解答群
b,c に関する解答群
エ i + 4 オ i + 64 カ i + 192
| 設問2 | 次の記述中の に入れる正しい答えを, 解答群の中から選べ。ここで,記述中の b と c には,設問1の正しい答えが入っているものとする。 |
文字コードを出現回数の降順に並べて印字する処理を追加する。追加した処理による印字例を, 図2に示す。印字の様式は,文字コードの並び順を除いて, 図1の3行目以降の様式と同じである。 同じ出現回数の文字コードは,それらを文字コードの昇順に並べる。

図2 追加した処理による印字例(出現回数順)
この処理のために,プログラムの行①の直後に,次の宣言を追加する。
int ih, ix, code[256];
さらに,プログラムの行②の位置に,次の整列処理部を追加する。
〔整列処理部〕
for(i = Ø; i <=255; i++)
code[i] = i;
③→ ih = 256;
④→ while (ih > Ø) {
⑤→ for(i = Ø; i < ih; i++) {
⑥→ if (freq[i] < freq[i+1]) {
Swap(code[i], code[i+1]);
Swap(freq[i], freq[i+1]);
⑦→
}
}
ih--;
}
printf("\n");
for (i =Ø; i < 64; i++) {
for (chr = i; chr <= b ; chr += c ) {
if ((Øx2Ø <= code[chr]) && (code[chr] <= Øx7E))
printf(" %1Øld %Ø2X '%c'", freq[chr], code[chr], code[chr]);
else
printf(" %1Øld %Ø2X ", freq[chr], code[chr]);
}
printf("\n");
}
ここで,整列処理部で使用する Swap(x, y) は,x と y の内容を入れ替えるために用意したマクロである。
整列処理部では,整列対象のデータ数が比較的少なく,また同じ出現回数の文字コードは 元の並び順が維持されるので,バブルソートを使用している。
行④の while 文のブロックを1回実行すると,配列の走査範囲(要素番号 0 ~ ih)中の 出現回数の最小値とその文字コードが,要素番号 ih の位置に置かれ,配列の走査範囲が 1 だけ狭められる。 これを繰り返して整列を行う。この処理では while 文のブロックの実行回数は常に d 回となる。
ここで,while 文のブロックの1回の繰返しにおいて,行⑥の if 文のブロック内の処理が 最後に実行されたときの i の値を ix とすると,行⑤の for 文のブロックの実行が終了した時点で, 配列 freq の要素番号 e 以降の要素の値は整列済みとなっている。これを利用して, 整列処理部を表1に示すように変更すれば,while 文のブロックの実行回数を減らせる可能性がある。
| 処置 | 変更内容 |
| f の直後に追加 | ix = Ø |
| 行⑦の位置に追加 | ix = i; |
| 行⑧を置換え | g |
d に関する解答群
e に関する解答群
f に関する解答群
g に関する解答群
[←前の問題] [次の問題→] [問題一覧表] [分野別] [基本情報技術者試験TOP ]
